
 D365 Business Central
D365 Business Central Netsuite
Netsuite


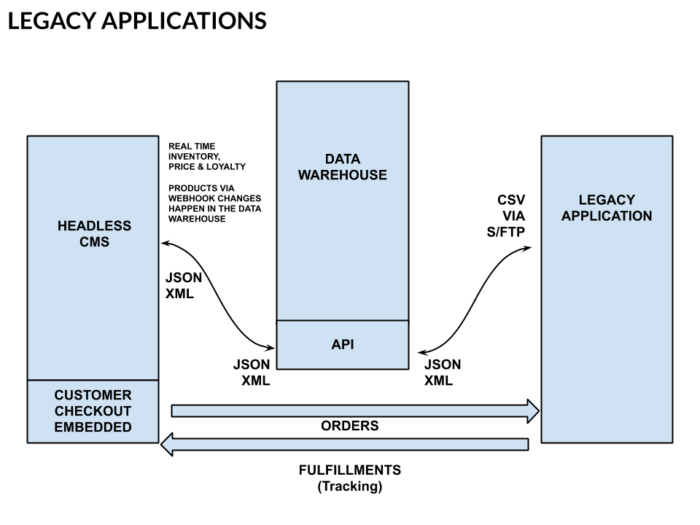
The Data Warehouse with Legacy Applications
In order to solve the data limitations of legacy applications, such as those that run on AS/400s or applications that have limited data import and export facilities, a data warehouse strategy needs to be adopted. Only data that is required for the application such as orders and fulfillment details need be interfaced directly to the legacy application. Real time live data that is required for product, inventory, pricing, and loyalty can be served up as needed from the data warehouse’s APIs. Orders would move from the checkout to the legacy application. Fulfillments would move in the same way, both being batch transfers.
This hybrid model won’t produce the cleanest headless setup but it will serve those with legacy applications. The image below details the workflows.
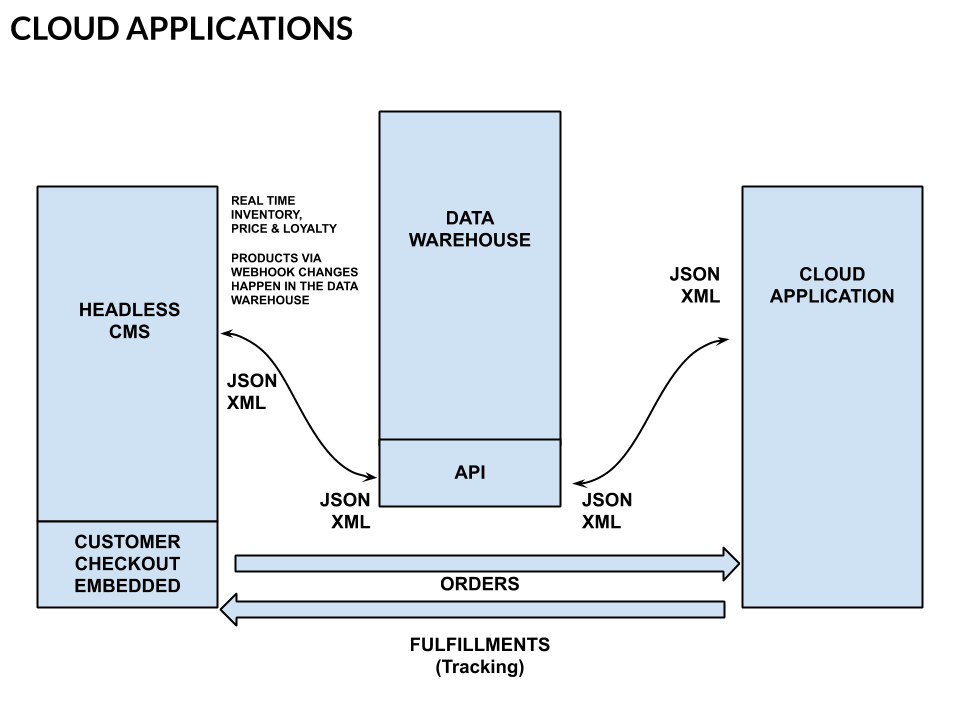
The Data Warehouse with Cloud-Based Applications
Cloud-based back office applications are generally more suited to a headless commerce world, as they presuppose an API infrastructure. There are, however, limitations with cloud-based API that may not be self-evident when initially architecting for a headless front end. This might include APIs that are not available for a specific function that is required in the headless configuration, SOAP-based APIs that are not designed for high transaction volumes, and general API latency that might affect the performance of the visual front end and hence the customer experience.
The data warehouse model works well in this model. As with the Legacy Application diagram, the Cloud Application workflows would be similar in nature except where data could be served up faster by using the cloud applications APIs rather than CSV based file. The files in this case would be XML or JSON depending on the APIs.
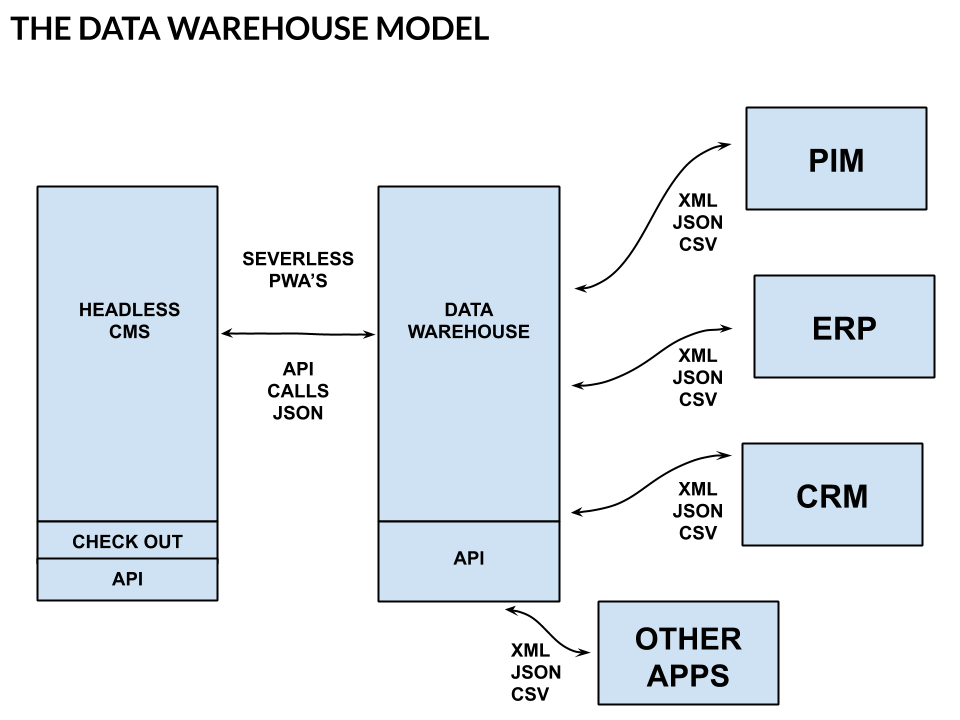
The Data Warehouse as the Data Source
In our previous two examples using both legacy applications and cloud based applications as the central point of truth for transactional information coupled with a data warehouse for product, price, and inventory data, headless commerce is achievable for most companies. Up to a certain transaction volume, this approach will satisfy most setups. An API-forward data warehouse for quick serverless requests via an API gateway can handle large volumes of requests for product, price, and inventory.
Where this model poses challenges is in situations where either the request volume is beyond the limits of the cloud API as a result of throttling, transaction volumes are too large or where the number of channels exceeds the capacity of the architecture to serve up data efficiently. This is where a data warehouse that is fed by all applications in the application stack and then served up as required by the headless frontend PWAs. For data from the headless front end and check out, data can be fed into the data warehouse for onward processing into the ERP without having to interact in the moment.
The structure and design of the data warehouse must be API-forward and driven from the ground up, and must include a semantic layer to accommodate the differing naming conventions and data types across all applications in the application stack.
This approach requires a more comprehensive approach to the front end design as well as the integration strategy, as we outlined in earlier articles.
In our three articles, we have explored the complexity of headless commerce and the requirement for a comprehensive integration strategy. In much of the material you find online, people speak of the ease of integration using APIs. Yet in all the articles, no one talks about the complexity of integration. Either it’s because so few people have actually done headless in the wild, or that the current use cases are not sophisticated enough to require complex integration strategies. For anyone contemplating headless, a proper and comprehensive integration strategy is key to a successful customer experience.
At VL we have architected the VL OMNI IPaaS platform as an API-forward data warehouse based solution that can scale as a company’s integration requirements scale. Due to our serverless-forward approach, we can handle transaction volumes at scale to and from multiple PWA requests from a variety of channels.
